Tseng-Hung Chen1 Yuan-Hong Liao1 Ching-Yao Chuang1 Wan-Ting Hsu1 Jianlong Fu2 Min Sun1
1National Tsing Hua University 2Microsoft Research
IEEE International Conference on Computer Vision (ICCV) 2017
|
Abstract:
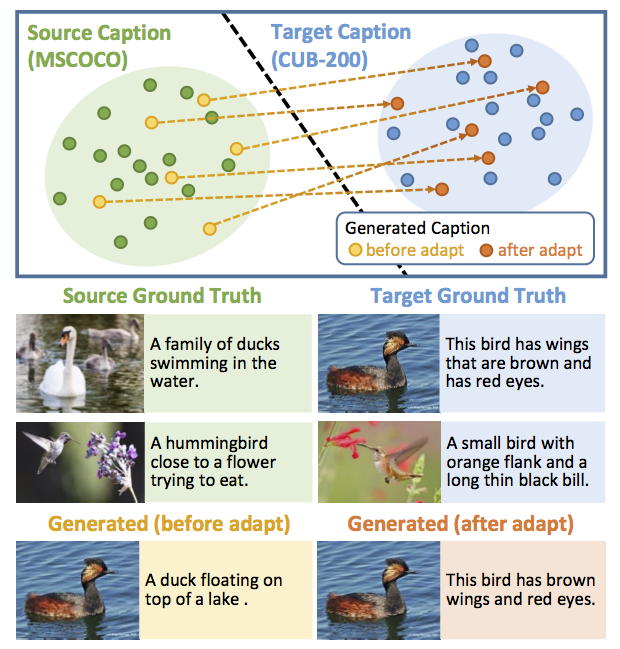
Impressive image captioning results are achieved in domains with plenty of training image and sentence pairs (e.g., MSCOCO). However, transferring to a target domain with significant domain shifts but no paired training data (referred to as cross-domain image captioning) remains largely unexplored. We propose a novel adversarial training procedure to leverage unpaired data in the target domain. Two critic networks are introduced to guide the captioner, namely domain critic and multi-modal critic. The domain critic assesses whether the generated sentences are indistinguishable from sentences in the target domain. The multi-modal critic assesses whether an image and its generated sentence are a valid pair. During training, the critics and captioner act as adversaries -- captioner aims to generate indistinguishable sentences, whereas critics aim at distinguishing them. The assessment improves the captioner through policy gradient updates. During inference, we further propose a novel critic-based planning method to select high-quality sentences without additional supervision (e.g., tags). To evaluate, we use MSCOCO as the source domain and four other datasets (CUB-200-2011, Oxford-102, TGIF, and Flickr30k) as the target domains. Our method consistently performs well on all datasets. In particular, on CUB-200-2011, we achieve 21.8% CIDEr-D improvement after adaptation. Utilizing critics during inference further gives another 4.5% boost.
|

|
@article{chen2017show,
title={Show, Adapt and Tell: Adversarial Training of Cross-domain Image Captioner},
author={Chen, Tseng-Hung and Liao, Yuan-Hong and Chuang, Ching-Yao and Hsu, Wan-Ting and Fu, Jianlong and Sun, Min},
journal={arXiv preprint arXiv:1705.00930},
year={2017}
}
|
 Code Code
 Paper
Supplementary Paper
Supplementary
|



















