|
|
IntroductionIn computer vision, CNNs trained on ImageNet have been the must-have initialization for a set of downstream tasks including object detection, semantic segmentation and pose estimation.
NLP shares the similar concept about transferring from large-scale data. Distributional representations such as word2vec (Mikolov et al., 2013) and GloVe (Pennington et al., 2014) have been common initializations for word embeddings in deep networks. Several works have shown a great success on multiple NLP tasks such as sentiment analysis, question answering, textual entailment and so on.
|
Transferring generic embeddings to specific use casesLearned in Translation: Contextualized Word VectorsIn particular, McCann et al. [1] from Salesforce use a machine translation encoder called CoVe and transfer it to other tasks. Experiment shows that training MT with the initialization of GloVe yields better performance. With the addition feature concatenation of GloVe and character n-gram embeddings further boosts the performance of all downstream tasks.
Deep contextualized word representations
Peters et al. [2] from AllenAI, on the other hand, take advantage of monolingual data, which is much easier to collect than a parallel corpus. The architecture of The Embeddings from Language Models (ELMo) is L-layers of bidirectional LSTMs (biLM) similar to their previous work TagLM [3] where token embeddings (CNN over characters) serve as input, except ELMo tie the parameters for both the token representation and Softmax layer in the forward and backward directions. For each token, a L-layer biLM computes a set of 2L + 1 representations (token representation, forward and backward hidden states in L layers). Then the final embeddings are computed by weighted-sum aggregation of L layers with regularization.
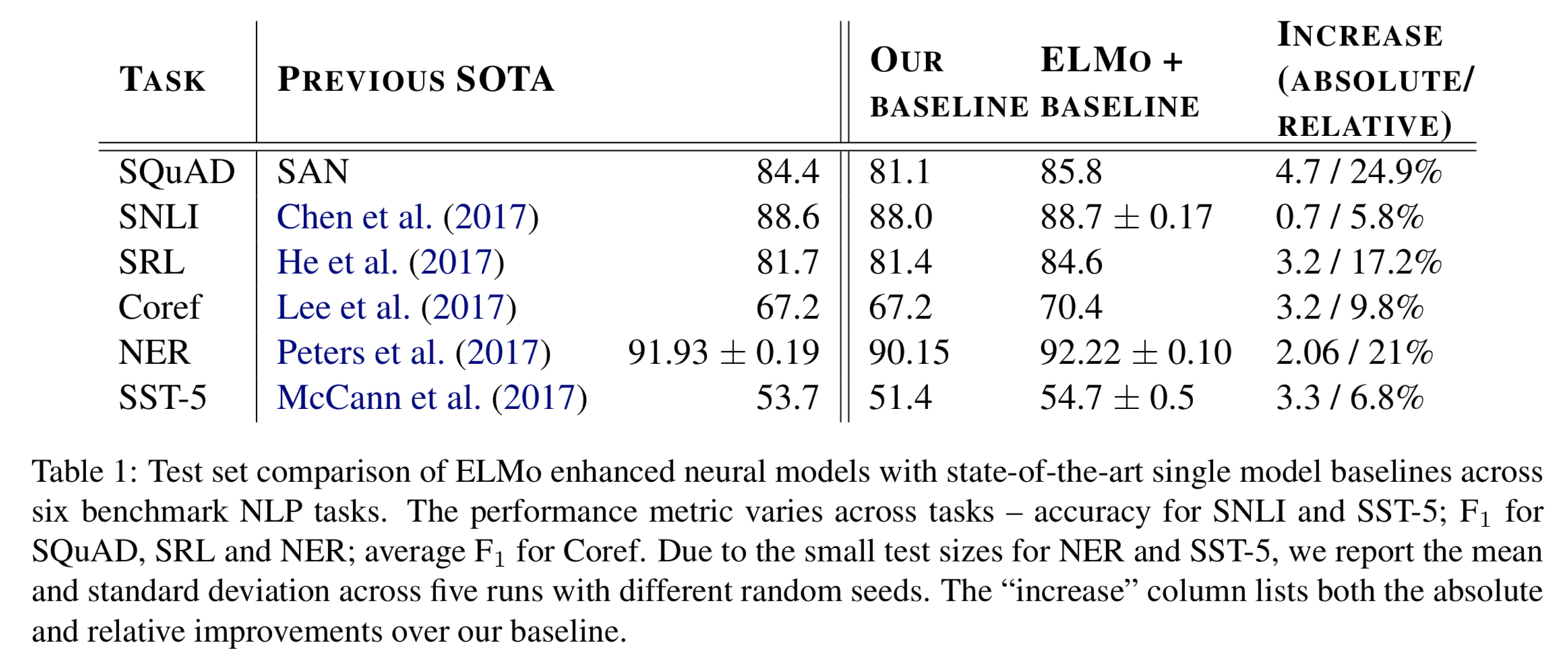
By training on a corpus containing 30 million sentences, it can learn very powerful word embeddings that capture both syntax and semantics. In order to prove that, they conduct extensive experiments on several language understanding problems including textual entailment, question answering, sentiment analysis, semantic role labeling, coreference resolution and named entity extraction. Performance shows that the addition of ELMo representations improves all previous state-of-the-art including CoVe.
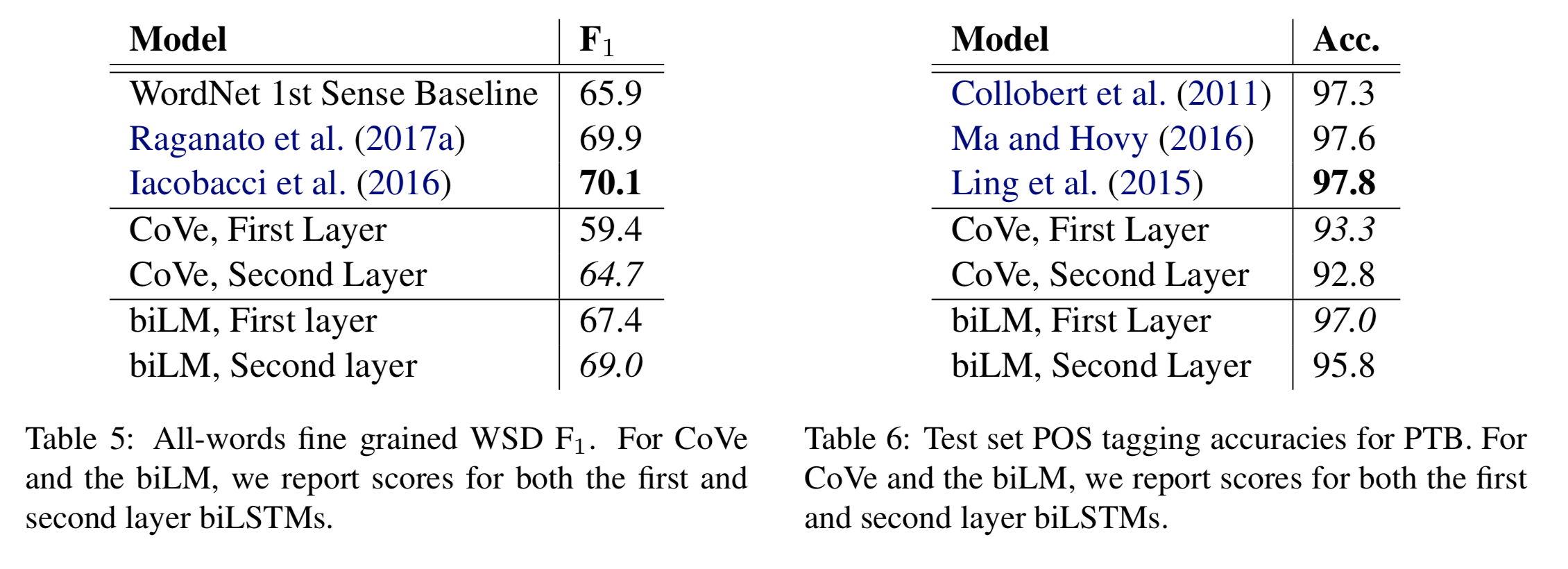
Finally, comparisons between CoVe and ELMo for POS tagging and word sense disambiguation further confirm the result of ELMo outperforms CoVe in downstream tasks.
|
Conclusion
To conclude, both papers prove that NLP tasks can benefit from large data. By leveraging either parallel MT corpus or monolingual corpus, there are several killer features in contextual word representation:
|
Reference
|
Tseng-Hung Chen |